 |
大庆达内IT培训学校 |
 4000872658
4000872658位置:搜学搜课 > 新闻 > 大庆Python培训学校就选达内

Python是一种通用的脚本开发语言,比其他编程语言更加简单、易学,其面向对象特性甚至比Java、C#、.NET更加彻底,因此非常适合开发。Python在软件质量控制、开发效率、可移植性、组件集成、库支持等方面均具有明显的优势。

行业
人才需求量大
|

前景
跟上人工智能时代的步伐
|
就业
就业领域广,就业方向多!
|

简单易学: 逻辑简单,语法更贴近英语,初中水平英语即可入门初级 Python工程师, Python的“前景广阔”却又“简单易学”吸引了不少低龄开发者;
0元开源: 逻Python开放源代码,共享时代,让 python变得更简单;
标 准 库: Python拥有强大易用的标准库,让编程更方便
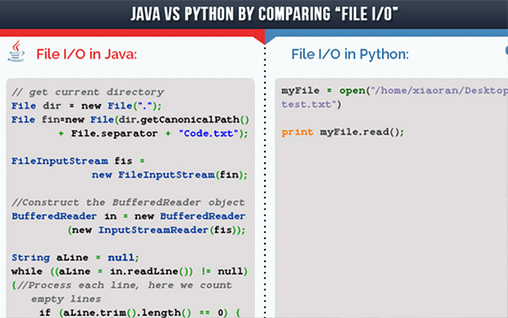
代码极短: 相同功能 Java VS Python代码数量对比,结果显而易见
一码多用: 可以用相同的代码处理不同规模的数据,达到用户的需求。
Our Courses
Our Teaching

讲师团队提供项目
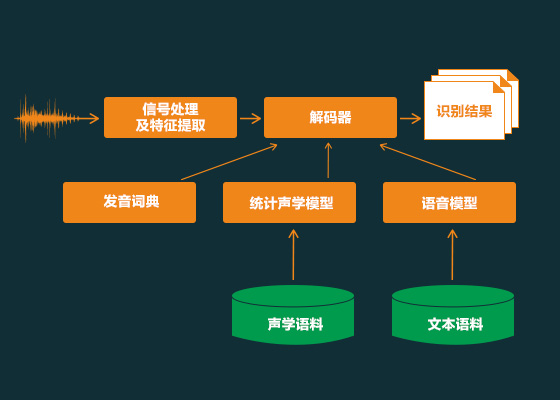
| 项目一:东方财富智能云系统 | 项目二:爬虫集群系统 | 项目三:语音识别 |
|

|
|
| 项目简介 | ||
| 在线金融交易系统,通过实时获取上证、深证所提供的证券金融数据,进行智能分析、显示,较终按照用户制定的交易策略进行虚拟交易。 | 通过对海量招聘数据挖掘、分析,帮助求职者更快更好的找到适合的工作。可以按照城市、薪资、行业、其他技能关键字等进行合理分析,较终得出有价值的结果。 | 采用Google的TensorFlow人工智能学习系统建立的智能语音识别系统。通过学习该项目,希望学员早日走入人工智能的大门。 |
| 技能掌握 | ||
|
1、Python核心技术,网络编程技术。 2、WEB前端开发技术:HTML5、CSS、Javascript、JQuery库、网页设计技能。 3、多种网络协议及数据格式,如:HTTP协议、JSCON。 4、数据库技术:MySql、MongoDB、Redis。 5、Django Web框架技术 6、Python SMTP smtplib、email模块 7、Python项目部署、测试技术 8、软件工程管理技能、Git、Pydoc等工具使用 |
1、熟练使用Python urllib requests等模块 2、掌握Python网络编程、多线程编程技术 3、掌握XML解析、XPath 语法,以及Python的re、json模块 4、掌握网络协议,如HTTP协议 5、理解分布式爬虫原理及实现 6、熟练使用Scrapy框架,及scrapy-redis分布式框架 |
1、掌握采用Tornado框架实现高并发请求技能。 2、掌握海量数据分析技术。 3、掌握语音识别技术原理、实现方法。 4、掌握采用Python作为开发语言的人工智能框架TensorFlow。 5、掌握第三方SDK的使用,如微软语音、百度语音的Python SDK。 6、掌握数据的云端存取访问技术 7、掌握Python图形编程技术。 |
诚信经营,拒绝虚假宣传是达内公司的经营理念。达内公司将在学员报名之前公布公开所有授课讲师的安排 及背景资料,并郑重公布《指定授课讲师承诺书》,确保学员利益。





大庆有没有Python培训班,欢迎咨询大庆达内Python培训班,IT培训选达内,17年专业IT培训机构,美国上市集团,开设IT培训班Java、python、大数据、linux、UI、会计等IT培训,泛IT培训和非IT培训共24大课程,了解更多相关培训课程欢迎咨询

1.什么是Python爬虫
Python爬虫,即网络Python爬虫,大家可以理解为在网络上爬行的一只蜘蛛,互联网就比作一张大网,而Python爬虫便是在这张网上爬来爬去的蜘蛛,如果它遇到资源,那么它就会抓取下来。想抓取什么?这个由你来控制它,通过特定的逻辑获取你想要的资源。
比如它在抓取一个网页,在这个网中他发现了一条道路,其实就是指向网页的超链接,那么它就可以爬到另一张网上来获取数据。这样,就可以爬取到你想要获取的东西了。
2.浏览网页的过程
用户浏览网页的过程中,我们可能会看到许多好看的图片,比如我们会看到几张的图片以及百度搜索框,这个过程其实就是用户输入网址之后,经过DNS服务器,找到服务器主机,向服务器发出一个请求,服务器经过解析之后,发送给用户的浏览器HTML、JS、CSS等文件,浏览器解析出来,用户便可以看到形形色色的图片了。
因此,用户看到的网页实质是基于HTML代码构成的,其余的样式以及各种绚丽的动画都是通过CSS和JS技术加载出来的。Python爬虫爬来的便是这些内容,通过分析和过滤这些HTML代码,实现对图片、文字等资源的获取。
3.URL的含义
URL是指统一资源定位符,也就是我们说的网址,统一资源定位符是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。互联网上的每个文件都有一个的URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它。
URL的格式由三部分组成:
①部分是协议(或称为服务方式)
②第二部分是存有该资源的主机IP地址(有时也包括端口号)
③第三部分是主机资源的具体地址,如目录和文件名等
Python爬虫爬取数据时必须要有一个目标的URL才可以获取数据,因此,它是Python爬虫获取数据的基本依据,准确理解它的含义对Python爬虫学习有很大帮助
4.对Python爬虫的误解的解释
Python爬虫不是的,但是没有Python爬虫是万万不能的,开个玩笑。其实Python爬虫并不是能自动的解决任何事情,而且爬虫也不是Python的专利,有了它能提高生产力那是一定的,但是你想让他向人一样的解决一切问题是不可能的。比如,识别图片,提取一段文字中的意思,这些单纯的靠Python爬虫技术是完不成的,请大家有一个清晰的认识。
尊重原创文章,转载请注明出处与链接:http://www.soxsok.com/wnews119987.html 违者必究! 以上就是关于“大庆Python培训学校就选达内”的全部内容了,想了解更多相关知识请持续关注本站。














