 |
徐州达内IT培训学校 |
 4000336024
4000336024位置:搜学搜课 > 新闻 > 徐州达内Python培训徐州分校地址

Python是一种通用的脚本开发语言,比其他编程语言更加简单、易学,其面向对象特性甚至比Java、C#、.NET更加彻底,因此非常适合开发。Python在软件质量控制、开发效率、可移植性、组件集成、库支持等方面均具有明显的优势。

行业
人才需求量大
|

前景
跟上人工智能时代的步伐
|
就业
就业领域广,就业方向多!
|

简单易学: 逻辑简单,语法更贴近英语,初中水平英语即可入门初级 Python工程师, Python的“前景广阔”却又“简单易学”吸引了不少低龄开发者;
0元开源: 逻Python开放源代码,共享时代,让 python变得更简单;
标 准 库: Python拥有强大易用的标准库,让编程更方便
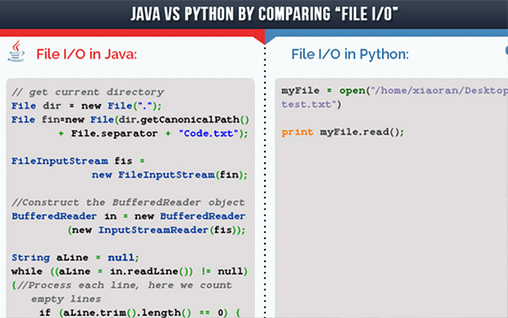
代码极短: 相同功能 Java VS Python代码数量对比,结果显而易见
一码多用: 可以用相同的代码处理不同规模的数据,达到用户的需求。
Our Courses
Our Teaching

讲师团队提供项目
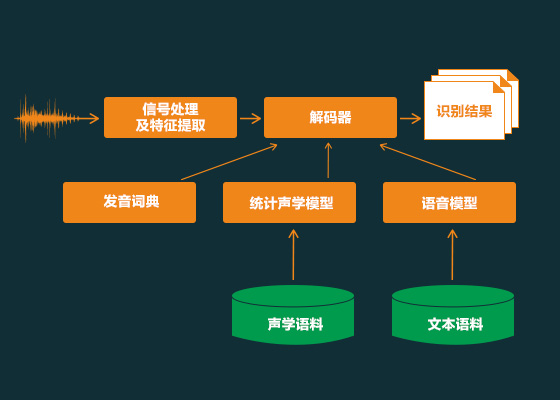
| 项目一:东方财富智能云系统 | 项目二:爬虫集群系统 | 项目三:语音识别 |
|

|
|
| 项目简介 | ||
| 在线金融交易系统,通过实时获取上证、深证所提供的证券金融数据,进行智能分析、显示,较终按照用户制定的交易策略进行虚拟交易。 | 通过对海量招聘数据挖掘、分析,帮助求职者更快更好的找到适合的工作。可以按照城市、薪资、行业、其他技能关键字等进行合理分析,较终得出有价值的结果。 | 采用Google的TensorFlow人工智能学习系统建立的智能语音识别系统。通过学习该项目,希望学员早日走入人工智能的大门。 |
| 技能掌握 | ||
|
1、Python核心技术,网络编程技术。 2、WEB前端开发技术:HTML5、CSS、Javascript、JQuery库、网页设计技能。 3、多种网络协议及数据格式,如:HTTP协议、JSCON。 4、数据库技术:MySql、MongoDB、Redis。 5、Django Web框架技术 6、Python SMTP smtplib、email模块 7、Python项目部署、测试技术 8、软件工程管理技能、Git、Pydoc等工具使用 |
1、熟练使用Python urllib requests等模块 2、掌握Python网络编程、多线程编程技术 3、掌握XML解析、XPath 语法,以及Python的re、json模块 4、掌握网络协议,如HTTP协议 5、理解分布式爬虫原理及实现 6、熟练使用Scrapy框架,及scrapy-redis分布式框架 |
1、掌握采用Tornado框架实现高并发请求技能。 2、掌握海量数据分析技术。 3、掌握语音识别技术原理、实现方法。 4、掌握采用Python作为开发语言的人工智能框架TensorFlow。 5、掌握第三方SDK的使用,如微软语音、百度语音的Python SDK。 6、掌握数据的云端存取访问技术 7、掌握Python图形编程技术。 |
诚信经营,拒绝虚假宣传是达内公司的经营理念。达内公司将在学员报名之前公布公开所有授课讲师的安排 及背景资料,并郑重公布《指定授课讲师承诺书》,确保学员利益。





达内致力于面向IT互联网行业,培养软件开发工程师、测试工程师、系统管理员、智能硬件工程师、UI设计师、网络营销工程师、会计等职场人才。2015年起,推出面向青少年的少儿编程、智能机器人编程、编程数学等K12课程。

python分析包pandas有哪些小技巧
了解python的同学都知道,Pandas是python的一个数据分析包,初由AQR Capital Management于2008年4月开发,并于2009年底开源出来,目前由专注于Python数据包开发的PyData开发team继续开发和维护,属于PyData项目的一部分。Pandas初被作为金融数据分析工具而开发出来,因此,pandas为时间序列分析提供了很好的支持。
既然有pandas这么的工具,使用它的人也会很多,今天,python培训班的小编就为大家归纳整理了一些工作中常用到的pandas使用技巧,方便更地实现数据分析。
1.计算变量缺失率
df=pd.read_csv('titanic_train.csv')
def missing_cal(df):
"""
df :数据集
return:每个变量的缺失率
"""
missing_series = df.isnull().sum()/df.shape[0]
missing_df = pd.DataFrame(missing_series).reset_index()
missing_df = missing_df.rename(columns={'index':'col',
0:'missing_pct'})
missing_df = missing_df.sort_values('missing_pct',ascending=False).reset_index(drop=True)
return missing_df
missing_cal(df)
如果需要计算样本的缺失率分布,只要加上参数axis=1.
2.获取分组里大值所在的行方法
分为分组中有重复值和无重复值两种。无重复值的情况。
df = pd.DataFrame({'Sp':['a','b','c','d','e','f'], 'Mt':['s1', 's1', 's2','s2','s2','s3'], 'Value':[1,2,3,4,5,6], 'Count':[3,2,5,10,10,6]})
df
df.iloc[df.groupby(['Mt']).apply(lambda x: x['Count'].idxmax())]
先按Mt列进行分组,然后对分组之后的数据框使用idxmax函数取出Count大值所在的列,再用iloc位置索引将行取出。有重复值的情况
df["rank"] = df.groupby("ID")["score"].rank(method="min", ascending=False).astype(np.int64)
df[df["rank"] == 1][["ID", "class"]]
对ID进行分组之后再对分数应用rank函数,分数相同的情况会赋予相同的,然后取出为1的数据。
3.多列合并为一行
df = pd.DataFrame({'id_part':['a','b','c','d'], 'pred':[0.1,0.2,0.3,0.4], 'pred_class':['women','man','cat','dog'], 'v_id':['d1','d2','d3','d1']})
df.groupby(['v_id']).agg({'pred_class': [', '.join],'pred': lambda x: list(x),
'id_part': 'first'}).reset_index()
4.删除包含特定字符串所在的行
df = pd.DataFrame({'a':[1,2,3,4], 'b':['s1', 'exp_s2', 's3','exps4'], 'c':[5,6,7,8], 'd':[3,2,5,10]})
df[df['b'].str.contains('exp')]
5.组内排序
df = pd.DataFrame([['A',1],['A',3],['A',2],['B',5],['B',9]], columns = ['name','score'])
介绍两种地组内排序的方法。
df.sort_values(['name','score'], ascending = [True,False])
df.groupby('name').apply(lambda x: x.sort_values('score', ascending=False)).reset_index(drop=True)
6.选择特定类型的列
drinks = pd.read_csv('data/drinks.csv')
# 选择所有数值型的列
drinks.select_dtypes(include=['number']).head()
# 选择所有字符型的列
drinks.select_dtypes(include=['object']).head()
drinks.select_dtypes(include=['number','object','category','datetime']).head()
# 用 exclude 关键字排除指定的数据类型
drinks.select_dtypes(exclude=['number']).head()
尊重原创文章,转载请注明出处与链接:http://www.soxsok.com/wnews300494.html 违者必究! 以上就是关于“徐州达内Python培训徐州分校地址”的全部内容了,想了解更多相关知识请持续关注本站。

南通IT软件培训

南通UI设计

南通软件开发培训












