 |
上海中公优Python培训机构 |
 4000857126
4000857126位置:搜学搜课 > 新闻 > 上海专业的python培训机构一览表

Python时代 你了解Python开发吗?

主流编程的一门语言
Python , 是一门简单易学、功能强大、灵活的编程语言。 它能够把用其他语言制作的各种模块很轻松地联结在一起,常被昵称为“胶水语言”。
功能强大的编程语言
Python可以说功能强大,系统运维、图形处理、数学处理、文本处理、数据库编程、网络编程、web编程、多媒体应用、pymo引擎、黑客编程、爬虫编写、机器学习、人工智能等等都用到python。
看重政策支持的语言
发布《新一代人工智能发展规划》,人工智能正式纳入发展战略。 已将人工智能划入高中新课标;全国计算机二级考试新“Python 语言程序设计”科目.....
企业越来越热衷语言
Python的应用特别广,国内外众多企业尤其是大型企业很多都在使用Python作为关键的开发语言之一,如谷歌、NASA、YouTube、Facebook、百度、阿里、网易、新浪、搜狐等等。
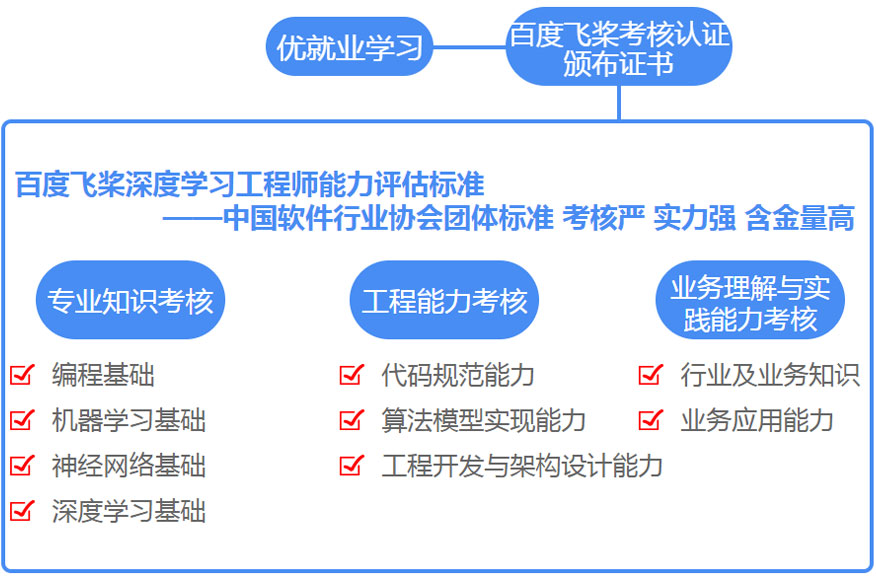
课程融入百度飞桨研发科技 教学内容再造升级
① 优就业的Python+人工智能课程融入百度飞桨研发提供的深度学习课程、学习教材以及前沿技术。助你从0开始学习人工智能开发。应用百度飞桨 AI Studio 实训平台 随时开展深度学习项目
②百度飞桨AI Studio是针对AI学习者的在线一体化开发实训平台,提供学员学习、技术进阶等不同需求。掌握专项解决方案、接触AI服务。学员可获 百度飞桨证书
③优就业作为百度深度学习首批合作伙伴,学员毕业可0元享受百度认证考试且通过认证后可获得百度深度学习认证,颁发百度飞桨PaddlePaddle深度学习初级工程师认证,获得认证学员有机会入职百度系公司。引入百度飞桨PaddlePaddle实训项目 参与人工智能火热未来
④项目贯穿式教学,优就业课程引入百度飞桨前沿实训项目,涉及到手写数字识别、文本分类、图片验证码识别等多项人工智能技术。

大数据分析工程师
平均工资:¥20030/月
人工智能工程师
平均工资:¥24350/月
Python开发工程师
平均工资:¥19960/月
Web全栈开发工程师
平均工资:¥16160/月
爬虫开发工程师
平均工资:¥19080/月
游戏开发工程师
平均工资:¥17490/月
搜索引擎工程师
平均工资:¥26660/月
运维自动化工程师
平均工资:¥13510/月





1、学不会怎么办?
2、学完能做什么?好就业吗?
3、0元试学真的不用掏一分钱吗?
4、想学习没有那么多学费怎么办?
5、非计算机专业基础差可以学习吗?
6、学费多少钱?学不会能退费吗?
优就业是中公教育IT培训品牌,致力于培养面向互联网领域的人才,以学员就业为目的,优质就业为宗旨,是一家集互联网营销师、UI/UE交互设计师、Web前端工程师、Java工程师、Python工程师、人工智能开发工程师、VR/AR开发工程师、Unity开发工程师、大数据工程师、Linux云计算工程师、软件测试工程师、PHP工程师、网络安全工程师、嵌入式开发工程师、三维可视化设计师、C/C++工程师、SEM竞价师、SEO优化师、社会化媒体运营师、电商运营师等课程为一体的IT培训机构。
为培养真正符合时代需求的IT人才,中公教育优就业以高瞻的视野,经多年布局,打造人才培训服务体系。以企业需求为导向,以行业未来为驱动,向企业和社会不断输送IT人才。
网络爬虫有什么用
“如何学Python”、“Python从入门到精通需要注意什么”成为一直困扰人们的问题。下面是小编为您整理的关于网络爬虫有什么用,希望对你有所帮助。
网络爬虫是什么
网络爬虫(Web
crawler),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本,它们被广泛用于互联网搜索引擎或其他类似网站,可以自动采集所有其能够访问到的页面内容,以获取或更新这些网站的内容和检索方式。从功能上来讲,爬虫一般分为数据采集,处理,储存三个部分。

传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分析结果还可能对以后的抓取过程给出反馈和指导。
相对于通用网络爬虫,聚焦爬虫还需要解决三个主要问题:
(1) 对抓取目标的描述或定义;
(2) 对网页或数据的分析与过滤;
(3) 对URL的搜索策略。
网络爬虫有什么用
1)爬虫支持多线程么、爬虫能用代理么、爬虫会爬取重复数据么、爬虫能爬取JS生成的信息么?
不支持多线程、不支持代理、不能过滤重复URL的,那都不叫开源爬虫,那叫循环执行http请求。
能不能爬js生成的信息和爬虫本身没有太大关系。爬虫主要是负责遍历网站和下载页面。爬js生成的信息和网页信息抽取模块有关,往往需要通过模拟浏览器(htmlunit,selenium)来完成。这些模拟浏览器,往往需要耗费很多的时间来处理一个页面。所以一种策略就是,使用这些爬虫来遍历网站,遇到需要解析的页面,就将网页的相关信息提交给模拟浏览器,来完成JS生成信息的抽取。
2)爬虫可以爬取ajax信息么?
网页上有一些异步加载的数据,爬取这些数据有两种方法:使用模拟浏览器(问题1中描述过了),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果是自己生成ajax请求,使用开源爬虫的意义在哪里?其实是要用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我所需要的ajax请求(列表),如何用这些爬虫来对这些请求进行爬取?
爬虫往往都是设计成广度遍历或者深度遍历的模式,去遍历静态或者动态页面。爬取ajax信息属于deep
web(深网)的范畴,虽然大多数爬虫都不直接支持。但是也可以通过一些方法来完成。比如WebCollector使用广度遍历来遍历网站。爬虫的轮爬取就是爬取种子集合(seeds)中的所有url。简单来说,就是将生成的ajax请求作为种子,放入爬虫。用爬虫对这些种子,进行深度为1的广度遍历(默认就是广度遍历)。
什么是网络爬虫,网络爬虫的职能是什么
网络蜘蛛即Web
Spider,是一个很形象的名字。把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛。网络蜘蛛是通过网页的链接地址来寻找网页,从
网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止。如果把整个互联网当成一个网站,那么网络蜘蛛就可以用这个原理把互联网上所有的网页都抓取下来。
对于搜索引擎来说,要抓取互联网上所有的网页几乎是不可能的,从目前公布的数据来看,容量的搜索引擎也不过是抓取了整个网页数量的百分之四十左右。这其中的原因一方面是抓取技术的瓶颈,无法遍历所有的网页,有许多网页无法从其它网页的链接中找到;另一个原因是存储技术和处理技术的问题,如果按照每个页面的平均大小为20K计算(包含图片),100亿网页的容量是100×2000G字节,即使能够存储,下载也存在问题(按照一台机器每秒下载
20K计算,需要340台机器不停的下载一年时间,才能把所有网页下载完毕)。同时,由于数据量太大,在提供搜索时也会有效率方面的影响。因此,许多搜索引擎的网络蜘蛛只是抓取那些重要的网页,而在抓取的时候评价重要性主要的依据是某个网页的链接深度。
在抓取网页的时候,网络蜘蛛一般有两种策略:广度和深度。
广度是指网络蜘蛛会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。这是常用的方式,因为这个方法可以让网络蜘蛛并行处理,提高其抓取速度。深度是指网络蜘蛛会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路之后再转入下一个起始页,
继续跟踪链接。这个方法有个优点是网络蜘蛛在设计的时候比较容易。两种策略的区别,下图的说明会更加明确。
由于不可能抓取所有的网页,有些网络蜘蛛对一些不太重要的网站,设置了访问的层数。例如,在上图中,A为起始网页,属于0层,B、C、D、
E、F属于第1层,G、H属于第2层,
I属于第3层。如果网络蜘蛛设置的访问层数为2的话,网页I是不会被访问到的。这也让有些网站上一部分网页能够在搜索引擎上搜索到,另外一部分不能被搜索到。对于网站设计者来说,扁平化的网站结构设计有助于搜索引擎抓取其更多的网页。
网络蜘蛛在访问网站网页的时候,经常会遇到加密数据和网页权限的问题,有些网页是需要会员权限才能访问。当然,网站的所有者可以通过协议让网
络蜘蛛不去抓取(下小节会介绍),但对于一些出售报告的网站,他们希望搜索引擎能搜索到他们的报告,但又不能完全**的让搜索者查看,这样就需要给网络蜘
蛛提供相应的用户名和密码。网络蜘蛛可以通过所给的权限对这些网页进行网页抓取,从而提供搜索。而当搜索者点击查看该网页的时候,同样需要搜索者提供相应的权限验证。
内容提取
搜索引擎建立网页索引,处理的对象是文本文件。对于网络蜘蛛来说,抓取下来网页包括各种格式,包括html、图片、doc、pdf、多媒体、
动态网页及其它格式等。这些文件抓取下来后,需要把这些文件中的文本信息提取出来。准确提取这些文档的信息,一方面对搜索引擎的搜索准确性有重要作用,另一方面对于网络蜘蛛正确跟踪其它链接有一定影响。
对于doc、pdf等文档,这种由专业厂商提供的软件生成的文档,厂商都会提供相应的文本提取接口。网络蜘蛛只需要调用这些插件的接口,就可以轻松的提取文档中的文本信息和文件其它相关的信息。
HTML等文档不一样,HTML有一套自己的语法,通过不同的命令标识符来表示不同的字体、颜色、位置等版式,如:、、等,提取文本信息时需要把这些标识符都过滤掉。过滤标识符并非难事,因为这些标识符都有一定的规则,只要按照不同的标识符取得相应的信息即可。但在识别这些信息的时候,需要同步记录许多版式信息,例如文字的字体大小、是否是标题、是否是加粗显示、是否是页面的关键词等,这些信息有助于计算单词在网页中的重要程度。同时,对于
HTML网页来说,除了标题和正文以外,会有许多广告链接以及公共的频道链接,这些链接和文本正文一点关系也没有,在提取网页内容的时候,也需要过滤这些
无用的链接。例如某个网站有“产品介绍”频道,因为导航条在网站内每个网页都有,若不过滤导航条链接,在搜索“产品介绍”的时候,则网站内每个网页都会搜索到,无疑会带来大量垃圾信息。过滤这些无效链接需要统计大量的网页结构规律,抽取一些共性,统一过滤;对于一些重要而结果特殊的网站,还需要个别处理。这就需要网络蜘蛛的设计有一定的扩展性。
对于多媒体、图片等文件,一般是通过链接的锚文本(即,链接文本)和相关的文件注释来判断这些文件的内容。例如有一个链接文字为“张曼玉照片
”,其链接指向一张bmp格式的图片,那么网络蜘蛛就知道这张图片的内容是“张曼玉的照片”。这样,在搜索“张曼玉”和“照片”的时候都能让搜索引擎找到这张图片。另外,许多多媒体文件中有文件属性,考虑这些属性也可以更好的了解文件的内容。
动态网页一直是网络蜘蛛面临的难题。所谓动态网页,是相对于静态网页而言,是由程序自动生成的页面,这样的好处是可以统一更改网页风格,也可以减少网页所占服务器的空间,但同样给网络蜘蛛的抓取带来一些麻烦。由于开发语言不断的增多,动态网页的类型也越来越多,如:asp、jsp、php
等。这些类型的网页对于网络蜘蛛来说,可能还稍微容易一些。网络蜘蛛比较难于处理的是一些脚本语言(如VBScript和JavaScript)生成的网页,如果要完善的处理好这些网页,网络蜘蛛需要有自己的脚本解释程序。对于许多数据是放在数据库的网站,需要通过本网站的数据库搜索才能获得信息,这些给网络蜘蛛的抓取带来很大的困难。对于这类网站,如果网站设计者希望这些数据能被搜索引擎搜索,则需要提供一种可以遍历整个数据库内容的方法。
对于网页内容的提取,一直是网络蜘蛛中重要的技术。整个系统一般采用插件的形式,通过一个插件管理服务程序,遇到不同格式的网页采用不同的插件处理。这种方式的好处在于扩充性好,以后每发现一种新的类型,就可以把其处理方式做成一个插件补充到插件管理服务程序之中。
更新周期
由于网站的内容经常在变化,因此网络蜘蛛也需不断的更新其抓取网页的内容,这就需要网络蜘蛛按照一定的周期去扫描网站,查看哪些页面是需要更新的页面,哪些页面是新增页面,哪些页面是已经过期的死链接。
学Python注意事项
开始学 Python一定要 注意 这 4 点:
1.代码规范,这本身就是一个非常好的习惯,如果开始不养好好的代码规划,以后会很痛苦 。
2.多动手,少看书,很多人学Python就一味的看书,这不是学数学物理,你看例题可能就会了,学习Python主要是学习编程思想。
3.勤练习,学完新的知识点,一定要记得如何去应用,不然学完就会忘,学我们这行主要都是实际操作。
4.学习要有效率,如果自己都觉得效率非常低,那就停不停,找一下原因,去问问过来人这是为什么 。
尊重原创文章,转载请注明出处与链接:http://www.soxsok.com/wnews528199.html 违者必究! 以上就是关于“上海专业的python培训机构一览表”的全部内容了,想了解更多相关知识请持续关注本站。

企业双选会

就餐环境

上课环境












