 |
运城达内IT教育学校 |
 4000336002
4000336002 位置:搜学搜课 > 新闻 > 运城Python培训学多久学费多少

Python是一种通用的脚本开发语言,比其他编程语言更加简单、易学,其面向对象特性甚至比Java、C#、.NET更加彻底,因此非常适合开发。Python在软件质量控制、开发效率、可移植性、组件集成、库支持等方面均具有明显的优势。

行业
人才需求量大
|

前景
跟上人工智能时代的步伐
|
就业
就业领域广,就业方向多!
|

简单易学: 逻辑简单,语法更贴近英语,初中水平英语即可入门初级 Python工程师, Python的“前景广阔”却又“简单易学”吸引了不少低龄开发者;
0元开源: 逻Python开放源代码,共享时代,让 python变得更简单;
标 准 库: Python拥有强大易用的标准库,让编程更方便
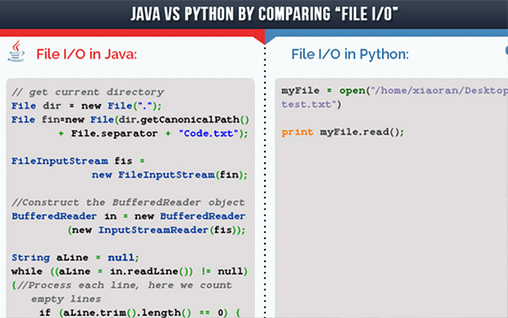
代码极短: 相同功能 Java VS Python代码数量对比,结果显而易见
一码多用: 可以用相同的代码处理不同规模的数据,达到用户的需求。
Our Courses
Our Teaching

讲师团队提供项目
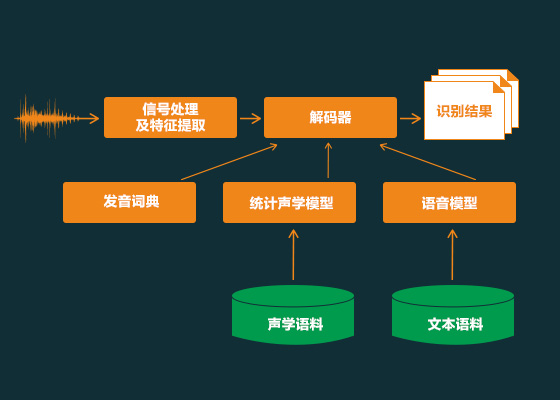
| 项目一:东方财富智能云系统 | 项目二:爬虫集群系统 | 项目三:语音识别 |
|

|
|
| 项目简介 | ||
| 在线金融交易系统,通过实时获取上证、深证所提供的证券金融数据,进行智能分析、显示,较终按照用户制定的交易策略进行虚拟交易。 | 通过对海量招聘数据挖掘、分析,帮助求职者更快更好的找到适合的工作。可以按照城市、薪资、行业、其他技能关键字等进行合理分析,较终得出有价值的结果。 | 采用Google的TensorFlow人工智能学习系统建立的智能语音识别系统。通过学习该项目,希望学员早日走入人工智能的大门。 |
| 技能掌握 | ||
|
1、Python核心技术,网络编程技术。 2、WEB前端开发技术:HTML5、CSS、Javascript、JQuery库、网页设计技能。 3、多种网络协议及数据格式,如:HTTP协议、JSCON。 4、数据库技术:MySql、MongoDB、Redis。 5、Django Web框架技术 6、Python SMTP smtplib、email模块 7、Python项目部署、测试技术 8、软件工程管理技能、Git、Pydoc等工具使用 |
1、熟练使用Python urllib requests等模块 2、掌握Python网络编程、多线程编程技术 3、掌握XML解析、XPath 语法,以及Python的re、json模块 4、掌握网络协议,如HTTP协议 5、理解分布式爬虫原理及实现 6、熟练使用Scrapy框架,及scrapy-redis分布式框架 |
1、掌握采用Tornado框架实现高并发请求技能。 2、掌握海量数据分析技术。 3、掌握语音识别技术原理、实现方法。 4、掌握采用Python作为开发语言的人工智能框架TensorFlow。 5、掌握第三方SDK的使用,如微软语音、百度语音的Python SDK。 6、掌握数据的云端存取访问技术 7、掌握Python图形编程技术。 |
诚信经营,拒绝虚假宣传是达内公司的经营理念。达内公司将在学员报名之前公布公开所有授课讲师的安排 及背景资料,并郑重公布《指定授课讲师承诺书》,确保学员利益。





运城Python培训学多久学费多少具体怎么收费根据你所在的城市消费水平以及选择的python辅导机构有关,详情可以电话咨询一下。运城达内教育为大家提供多种Python课程,集训营、周末班、线上课程等等,不同班次收费标准不同,详情欢迎来电咨询。接下来小编为您分享,一行Python代码训练所有分类或回归模型
import pandas as pd
from sklearn.model_selection import train_test_split
# Read the titanic dataset
df_cls = pd.read_csv("titanic.csv")
df_clsdf_cls = df_cls.drop(['PassengerId','Name','Ticket', 'Cabin'], axis=1)
# Drop instances with null records
df_clsdf_cls = df_cls.dropna()
# feature processing
df_cls['Sex'] = df_cls['Sex'].replace({'male':1, 'female':0})
df_cls['Embarked'] = df_cls['Embarked'].replace({'S':0, 'C':1, 'Q':2})
# Creating train test split
y = df_cls['Survived']
X = df_cls.drop(columns=['Survived'], axis=1)
# Call train test split on the data and capture the results
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42, test_size=0.2)
在特征工程和将数据分成训练测试数据之后,我们可以使用LazyPredict进行模型训练。
# LazyClassifier Instance and fiting data
cls= LazyClassifier(ignore_warnings=False, custom_metric=None)
models, predictions = cls.fit(X_train, X_test, y_train, y_test)
回归任务:
类似于分类模型训练,LazyPredict附带了回归数据集的自动模型训练。实现类似于分类任务,在实例LazyRegressor中的更改。
import pandas as pd
from sklearn.model_selection import train_test_split
# read the data
column_names = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV']
df_reg = pd.read_csv("housing.csv", header=None, delimiter=r"\s+", names=column_names)
# Creating train test split
y = df_reg['MEDV']
X = df_reg.drop(columns=['MEDV'], axis=1)
# Call train_test_split on the data and capture the results
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42, test_size=0.2)
reg = LazyRegressor(ignore_warnings=False, custom_metric=None)
models, predictions = reg.fit(X_train, X_test, y_train, y_test)
观察上述性能指标,Adaboost分类器是分类任务的性能模型,渐变增强的替换机策略模型是回归任务的表现模型。
结论:
在本文中,我们已经讨论了LazyPredict库的实施,这些库可以在几行Python代码中训练大约70个分类和回归模型。它是一个非常方便的工具,因为它给出了模型执行的整体情况,并且可以比较每个模型的性能。
每个模型都训练,默认参数,因为它不执行HyperParameter调整。选择执行模型后,开发人员可以调整模型以进一步提高性能。
文章来源:51CTO
温馨提示:为了不影响您的时间,来校区前或者遇到不明白的问题请先电话咨询,方便我校安排相关课程的专业老师为您解答,选取适合您的课程。以上是运城达内教育的小编为您分享的关于一行Python代码训练所有分类或回归模型的内容,希望可以为同学们提供帮助,更多Python资讯请持续关注运城达内教育。
尊重原创文章,转载请注明出处与链接:http://www.soxsok.com/wnews532059.html 违者必究! 以上就是关于“运城Python培训学多久学费多少”的全部内容了,想了解更多相关知识请持续关注本站。












