 |
上海中公优大数据培训机构 |
 4000857126
4000857126位置:搜学搜课 > 新闻 > 上海大数据培训机构哪家好一览表

大数据来袭,你准备好推塔了吗?
大数据是一种在获取、存储、管理、分析等方面大大超出了传统数据库软件工具能力范围的数据集合。它具有大量的数据规模、的数据流转、多样的数据类型和价值密度低四大特征。 未来大数据相关人才缺口巨大。
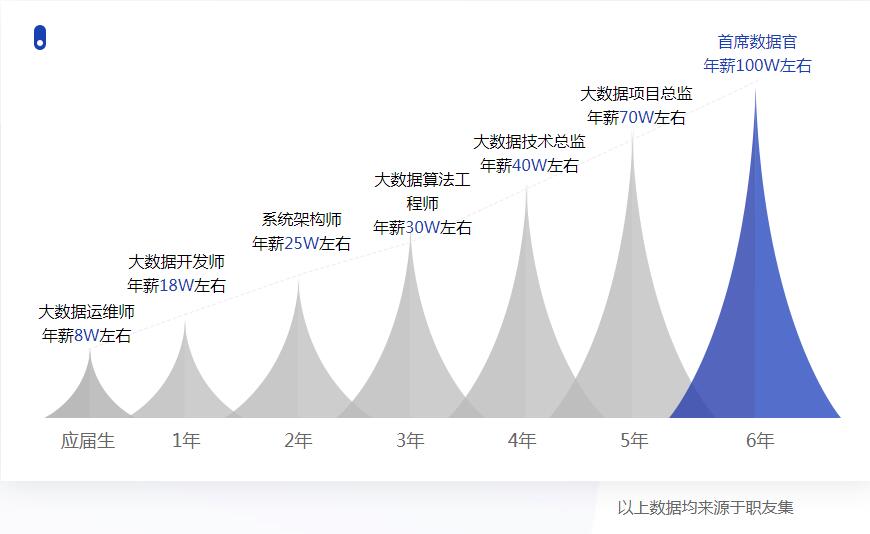
大量优质岗位等你来

薪资待遇随工作年限呈阶梯式上涨
只有想不想学,没有能不能学
理论、实战双向并行,奠定入行扎实基础
第 一阶段
Java基础:
Java基础语法 面向对象编程 常用类和工具类 集合框架体系 异常处理机制 文件和IO流 移动开户管理系统 多线程 枚举和垃圾回收 反射 JDK新特性通讯录系统
培养方向:
Java基本语法中的常量、变量声明和使用、运算符、数据类型以及相互转换、分支结构、循环结构、方法的定义和使用、数组、内存结构; 面向对象的编程思想;掌握类和对象的定义和使用;理解封装、继承、多态等特性;掌握抽象类接口的特点和使用方式;充分理解并运用Java面向对象思想来进行程序开发; 熟练使用常用类解决复杂问题;掌握异常的体系和处理机制;深入理解集合类的特点和底层实现原理;掌握集合类的常用方法;熟练掌握File类和多种IO流读写其他设备数据的方法;培养阅读源码的习惯和能力;
Java多线程的概念、原理、创建方式、同步、线程池技术;掌握Java的反射机制以及JDK的新特性
职业方向:初级Java工程师
第二阶段
JavaEE核心:
前端技术 数据库 JDBC技术 服务器端技术 Maven Spring SpringBoot Git
培养方向:
静态的网页技术,并且可以制作精美的网页和动态JavaScript效果完成项目前端页面的制作; MySQL数据库的基本操作和SQL语言对数据库的CRUD操作; JDBC连接数据库技术;数据库事务以及JDBC事务控制方式; 连接池的使用;DBUtils工具的使用,完成对数据库的CRUD操作; 服务器基本使用;Web工程创建; 服务器技术结合前端和数据库技术,使用MVC模式进行B/S架构项目的开发工作; Maven项目构建和管理; 熟悉Spring模块结构和作用;如何对组件对象进行参数注入;Spring声明式事务处理;理解SpringIOC和SpringAOP; 使用SpringBoot简化项目开发; 常用版本控制器Git的使用
职业方向:初中级Java工程师
第三阶段
Hadoop生态体系:
Linux Hadoop ZooKeeper Hive HBase Phoenix Impala Kylin Flume Sqoop&DataX Kafka Oozie&Azkaban Hue 智慧农业数仓分析平台
培养方向:
Linux操作系统安装及基本命令;shell脚本编程; 大数据架构Hadoop原理及编程使用;熟悉大数据框架Hadoop调优ZooKeeper工作机制,以及动态感知原理及使用; Hive数据仓库的使用及调优原理; HBase数据库的开发、使用以及调优; Phoenix基本使用; Impala查询使用; Kylin大数据的OLAP引擎; Flume数据迁移工具; Sqoop与DataX离线数据迁移工具及数据迁移测试; Kafka消息队列; Oozie、Azkaban项目流程调度开发工具; Hue开源Hadoop UI系统;掌握Hue与各个大数据组件的搭配使用; 各个大数据组件在项目中的实战使用;
职业方向:大数据开发工程师
第四阶段
Spark生态体系:
Scala、Spark、交通领域汽车流量监控项目、Flink
培养方向:
Scala多范式编程语言编写程序; Spark大数据计算框架原理;Spark实时流处理技术;Spark大数据计算框架调优;要求能够对不同业务场景下Spark Core、Spark Streaming、Spark SQL的技术选型有足够认知,能够熟练使用Spark Core、Spark Streaming、Spark SQL完成对应功能; Flink实时流处理技术;熟悉项目中应用开发
职业方向:大数据Spark开发工程师
第五阶段
项目实战+机器学习:
高铁智能检测系统、电信充值、中国天气网、机器学习
培养方向:
熟悉大数据开发基本流程和技术架构; 熟悉机器学习算法理论基础; 熟悉Python语言基础及数据算法库; 熟悉机器学习应用场景;
熟悉Spark机器学习框架; 熟悉数据分析平台开发全流程; 熟悉大数据推荐系统的开发全流程
职业方向:中级大数据工程师
第六阶段
就业指导:
企业面试前期准备与技巧 专业指导 企业面试复盘
课程内容:
1、职业规划讲解 2、简历注意事项详解 3、就业情况分析简历制作(个人技能、项目经验、自我评价) 1、简历审核修正 2、常见面试题的讲解 3、技术简历的指导与优化 4、强化实战项目(项目模块的介绍,业务流程的梳理)
真实面试复盘(晚自习时间)(总结学员面试中的问题,进行针对性的辅导以及相关面试题的讲解)
培养方向:
从简历、面试技巧等层面助力学员,培养学员沟通表达能力 让学员清晰了解职业发展规划,明确自身定位,找到适合自身发展的工作;
通过项目强化、面试专项指导、面试复盘等,学员能更好就业
企业级项目实战 匹配企业技能需求
项目名称:高铁电务设备智能监控大数据平台
项目介绍:
铁路信号设备是指挥列车运行、增加行车安全、提高运输效率、改善行车组织方式、实现行车指挥现代化的关键设施,在铁路运输生产过程中发挥着重要的作用。
为提高信号设备维修管理水平,进一步深化信号设备维修智能化应用,加强事前预防与预警、过程控制与监控、应急响应与处置、事后分析与评估等关键环节信息技术支撑,亟需建设铁路信号设备设施技术状态大数据应用(以下简称信号大数据应用),实现信号设备全寿命周期状态管理,建立科学的分析评价体系,全面掌握信号设备工作状态及运用情况,提高设备维修维护质量,降低铁路信号运营维护成本,提升信号设备的运输安全保障能力。
提升设备使用寿命,减少设备浪费,保障铁路安全。
项目效果图:

项目名称:智能广告推荐系统
项目介绍:
网络和智能终端的普及带来了海量人群的上网行为数据,大数据 技术的发展让细分人群的特性成为可能。不同的人群,网络行为习惯
差异性比较大,时间、地区、季节、节日、天气… …大量的因素,大量的数据交 织在一起,没有细分研究,对于大数据的分析,难以为广告主带来高价值。细分研究各类因素大数据,为广告主创造更高价值。
较终节省成本,投放广告。
项目效果图:
项目名称:移动充值项目
项目介绍:
中国移动公司旗下拥有很多的子机构,基本可以按照省份划分. 而各省份旗下的充值机 构也非常的多. 目前要想获取整个平台的充值情况,需要先以省为单元,进行省份旗下的机构统计,然后 由下往上一层一层的统计汇总,过程太过繁琐,且统计周期太长. 且充值过程中会涉及到中国 移动信息系统内部各个子系统之间的接口调用, 接口故障监控也成为了重点监控的内容之 一. 为此建设一个能够实时监控全国的充值情况的平台,
掌控全网的实时充值, 各接口调用 情况意义重大.
项目效果图:

一路暖心服务,不怕您货比三家
优就业
1、手把手教学,每一位学员的疑问随时解决,不拖延!
2、四分理论六分实战的合理教学,干货满满,课程实在,不闲扯!
3、真实项目Leader,行业经验、案例精髓,毫无保留倾囊相授!
4、真实项目实战,作品真正上线,学习的成果显而易见!
5、职业测评、简历修改、面试指导,企业推荐,打造个性化、差异化就业流程!
6、封闭教学包住宿,图书用户特惠等各项优惠,为你的学习做好服务!
其他机构
大班授课,老师精力有限,学员问题无法及时得到解决。
纯理论填鸭式教学,知识点抽象干瘪,不能学以致用。
案例陈旧,无法适应较新需求,小众非典型案例,不具行业代表性。
短暂虚拟操作,方法一带而过,学员对知识一知半解。
指导学员简历作假,或干脆无就业服务,无法按学员真实情况推荐就业,就业不稳定或薪资达不到预期。
日常管理散漫,食宿自理,后续费用接踵而至,经济压力大,影响学习质量。
现在报班 立享优惠!
就业促进班
针对人群:全日制、封闭式教学
周末班
针对人群:工作日上班,想利用周末时间学习新的专业技能
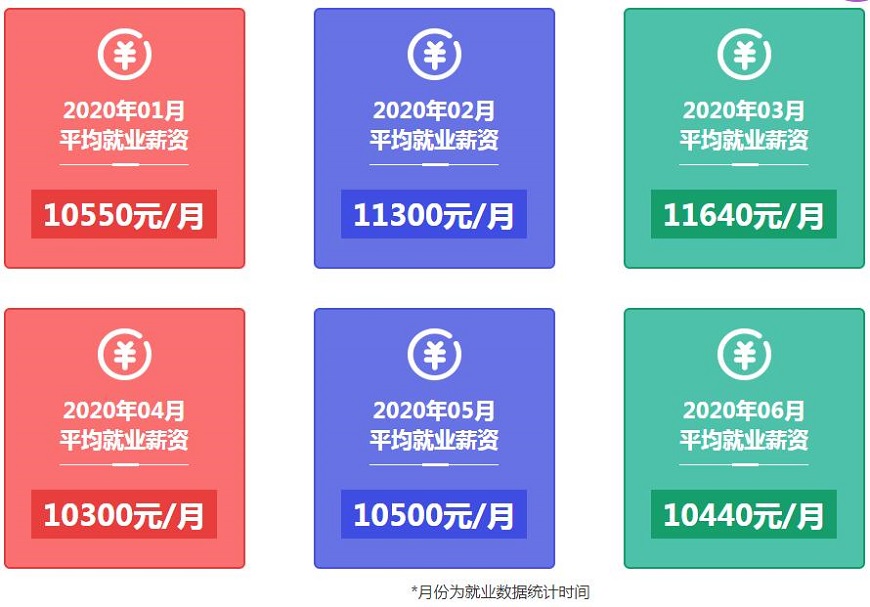
大数据毕业学员薪资统计
数据来源于内部学员就业情况统计,非广告宣传
优就业学员专享 八大福利
我们的学员值得更好的选择

高配置的教学环境,稳健的后勤服务
舒适住宿待遇,酒店式标准间,空调暖气开放,独立卫浴一应俱全,提供被褥及日常洗漱用品,24小时热水,专人打扫。

宽敞洁净的就餐环境,规律有序的就餐时间,营养搭配,让你享受舒心的学习。

优就业拥有优化合理的教学资源配置,空调教室,全苹果设备,一人一桌一电脑。让你拥有一个舒心的上课环境。

优就业培训基地拥有幽静安然的学习环境,无丝竹之乱耳,无市井之嘈音,让你在IT培训的路上保持独有的宁静。

优就业大数据培训,课程内容紧跟互联网技术发展与企业实际用人需求,不断升级更新。学员以Java语言夯实基础,学习Hadoop生态体系、Spark生态体系,融入大数据智慧农业数仓、交通领域汽车流量监控项目、高铁智能检测系统等项目作为实训内容,对大数据知识融会贯通,成长为真正的大数据人才。
理论、实战双向并行,奠定入行扎实基础
阶段一:Java语言基础:Java语言入门、基本语法、面向对象、常用API、异常、集合、IO流、多线程、网络编程、反射、JDK新特性、MySQL数据库、JDBC
阶段二:Hadoop技术栈:Linux、Hadoop、ZooKeeper、Hive、HBase、海王星大数据金融平台
阶段三:Spark技术栈:Scala、Kafka、Spark、交通流量实时可视化大屏
阶段四:Flink流式处理框架:Flink、ClickHouse、畅游天涯旅游实时分析项目
阶段五:项目实战:EWR消费信用风险舆情系统、Monoceros物流大数据平台、物流Kubernetes+Docker项目迁移
就业指导:企业面试前期准备与技巧、专业指导、企业面试复盘
优就业一路暖心服务,不怕您货比三家
1、手把手教学,每一位学员的疑问随时解决,不拖延!
2、四分理论六分实战的合理教学,干货满满,课程实在,不闲扯!
3、真实项目Leader,行业经验、案例精髓,毫无保留倾囊相授!
4、真实项目实战,作品真正上线,学习的成果显而易见!
5、职业测评、简历修改、面试指导,企业推荐,打造个性化、差异化就业流程!
6、封闭教学包住宿,中公购书补助等各项福利,为你的学习做好服务!

Apache Spark的局限性是什么?
Apache Spark是行业中流行和广泛使用的大数据工具之一。Apache Spark已成为业界的热门话题,并且如今非常流行。但工业正在转移朝向apache flink。
Apache Spark简介
Apache Spark是为计算而设计的开源,闪电般的集群计算框架。Apache Spark扩展了MapReduce模型,以有效地将其用于多种计算,包括流处理和交互式查询。Apache Spark的主要功能是内存中的群集计算,可以提高应用程序的处理速度。
Spark计划用于涵盖各种工作负载,例如迭代算法,批处理应用程序,流和交互式查询。除了支持这些工作负载,它还减少了维护不同工具的管理障碍。
Apache Spark框架的核心组件
Apache Spark框架由负责Spark功能的主要五个组件组成。这些组成部分是–
Spark SQL和数据框架–在顶部,Spark SQL允许用户运行SQL和HQL查询以处理结构化和半结构化数据。
SparkStreaming – Spark流传输有助于处理实时流数据,即日志文件。它还包含用于处理数据流的API
MLib机器学习– MLib是具有机器学习功能的Spark库。它包含各种机器学习算法,例如回归,聚类,协作过滤,分类等。
GraphX –支持图形计算的库称为GraphX。它使用户能够执行图操作。它还提供了图形计算算法。
Apache Spark Core API –它是Spark框架的内核,并提供了一个执行Spark应用程序的平台。
下图清楚地显示了Apache Spark的核心组件。
Apache Spark的局限性
用户在使用它时必须面对Apache Spark的一些限制。本文完全侧重于Apache Spark的限制以及克服这些限制的方法。让我们详细阅读Apache Spark的以下限制以及克服这些Apache Spark限制的方法。
1.没有文件管理系统
Apache Spark中没有文件管理系统,需要与其他平台集成。因此,它依赖于Hadoop等其他平台或任何其他基于云的文件管理系统平台。这是Apache Spark的主要限制之一。
2.不进行实时数据处理
Spark不完全支持实时数据流处理。在Spark流中,实时数据流被分为几批,称为Spark RDD(弹性分布式数据库)。在这些RDD上应用诸如join,map或reduce等操作来处理它们。处理后,结果再次转换为批次。这样,Spark流只是一个微批处理。因此,它不支持完整的实时处理,但是有点接近它。
3.昂贵
在谈论大数据的经济处理时,将数据保存在内存中并不容易。使用Spark时,内存消耗非常高。Spark需要巨大的RAM来处理内存。Spark中的内存消耗非常高,因此用户友好性并不高。运行Spark所需的额外内存成本很高,这使Spark变得昂贵。
4.小文件发行
当我们将Spark与Hadoop一起使用时,存在文件较小的问题。HDFS附带了数量有限的大文件,但有大量的小文件。如果我们将Spark与HDFS一起使用,则此问题将持续存在。但是使用Spark时,所有数据都以zip文件的形式存储在S3中。现在的问题是所有这些小的zip文件都需要解压缩才能收集数据文件。
仅当一个核心中包含完整文件时,才可以压缩zip文件。仅按顺序刻录核心和解压缩文件需要大量时间。此耗时的长过程也影响数据处理。为了进行有效处理,需要对数据进行大量改组。
5.延迟
Apache Spark的等待时间较长,这导致较低的吞吐量。与Apache Spark相比,Apache Flink的延迟相对较低,但吞吐量较高,这使其比Apache Spark更好。
6.较少的算法
在Apache Spark框架中,MLib是包含机器学习算法的Spark库。但是,Spark MLib中只有少数几种算法。因此,较少可用的算法也是Apache Spark的限制之一。
7.迭代处理
迭代基本上意味着重复使用过渡结果。在Spark中,数据是分批迭代的,然后为了处理数据,每次迭代都被调度并一个接一个地执行。
8.窗口标准
在Spark流传输中,根据预设的时间间隔将数据分为小批。因此,Apache Spark支持基于时间的窗口条件,但不支持基于记录的窗口条件。
9.处理背压
背压是指缓冲区太满而无法接收任何数据时,输入/输出开关上的数据累积。缓冲区为空之前,无法传输数据。因此,Apache Spark没有能力处理这种背压,但必须手动完成。
10.手动优化
使用Spark时,需要手动优化作业以及数据集。要创建分区,用户可以自行指定Spark分区的数量。为此,需要传递要固定的分区数作为并行化方法的参数。为了获得正确的分区和缓存,应该手动控制所有此分区过程。
尽管有这些限制,但Apache Spark仍然是流行的大数据工具之一。但是,现在已经有许多技术取代了Spark。Apache Flink是其中之一。Apache Flink支持实时数据流。因此,Flink流比Apache Spark流更好。
总结
每种工具或技术都具有一些优点和局限性。因此,Apache Spark的限制不会将其从游戏中删除。它仍然有需求,并且行业正在将其用作大数据解决方案。较新版本的Spark进行了不断的修改,以克服这些Apache Spark的局限性。
尊重原创文章,转载请注明出处与链接:http://www.soxsok.com/wnews684774.html 违者必究! 以上就是关于“上海大数据培训机构哪家好一览表”的全部内容了,想了解更多相关知识请持续关注本站。

住宿环境

就餐环境

上课环境












